


Fagbladet Journalisten bad mig pege på medieproduktioner/historier i 2014, der metodisk eller indholdsmæssigt er en forsmag på, hvad vi kommer til at opleve i 2015. Her er mit umiddelbare bud.
Robotter på fremmarch
Vi vil se flere artikler og tekster – store og små – der ikke er skrevet af journalister, men af robotter eller computerprogrammer. Men heldigvis er der god brug for journalisterne til at skrive de algoritmer og robotter, som skal producere artiklerne.
Et enkelt eksempel vakte megen opsigt i år, da et script næsten af sig selv producerede en lille historie til LA Times om et mindre jordskælv. Medieopmærksomheden var lidt pudsig, da det bestemt ikke var første gang, at jordskævsrobotten var på vagt.

Desuden var dette eksempel ikke anderledes end mange tilsvarende “robot”-tekster, vi i Kaas & Mulvad selv har skabt i de senere år for forskellige kunder.
Fordi live data i større og større omfang er til stede, vil vi meget snart se flere autogenererede tekster. Det vil være direkte ejendommeligt, hvis ikke medierne griber chancen og forsøger sig inden for dette område. Der er masser af steder, hvor de tekster, der i dag produceres, allerede er så ensartede og standardiserede, at de næsten kunne være skrevet af en computer. Finans/børs-journalistik og sportsjournalistik er nærliggende eksempler.
Mere datavisualisering
Vi vil se meget mere datavisualisering – og vi vil se både gode og dårlige eksempler.. Forhåbentlig får vi en masse gode visualiseringer, der brugt rigtigt kan formidle bedre, end tal og tekst alene kan. Men det er faktisk ikke så let at lave. Så vi vil helt sikkert også se en stribe af den anden slags, hvor visualiseringen ikke hjælper, men tværtimod gør det mere uoverskueligt og sværere at forstå. Enten fordi der bruges værktøjer, der skaber “færdige” visualiseringer, som skal passe til alle datasæt. Og derfor ikke rigtig passer til nogen. Eller fordi den, der skaber visualiseringerne, lader sig friste af de mange muligheder og ender med at overlæsse dem – og glemmer det vigtigste; at også visualiseringer skal vinkles skarpt.
Egne datasæt
Vi vil se flere historier baseret på datasæt, som medierne og journalisterne selv skaber. Det kan være ved hjælp af crowdsourcing (et nyere eksempel er TV2’s kort over mobilhuller, eller måske ved web scraping.
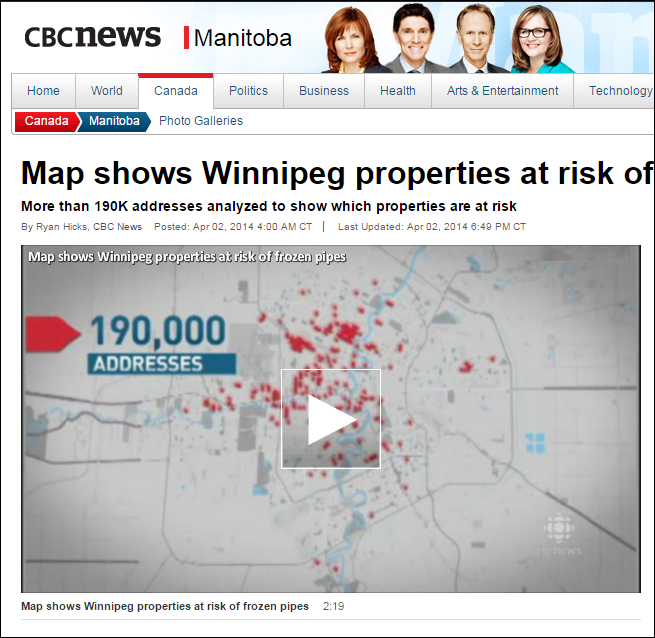
Et 2014-eksempel på data via web scraping er dette, hvor vi for Canadiske CBC skaffede myndighedernes data. I over 1200 huse i Winnipeg var vandrørene frosne, og myndighederne stillede blot en tjeneste til rådighed, hvor man kunne slå én adresse op og se status for præcis denne adresse. For CBC undersøgte vi samtlige adresser i byen og hjalp dem med data, så de kunne lave en god dækning.
Data som underholdning
Ud fra vores egne oplevelser med A4’s “Navnehjulet” spår jeg også, at vi vil se flere forsøge sig med at lave features, der er baseret på store datamængder, og som på samme tid er både saglige og underholdende. Vores erfaringer har jo vist, at den slags kan blive virkeligt store virale hits, og det vil der helt sikkert blive eksperimenteret videre med.
Myndighedernes “Big Data” kommer i spil
Hveranden konference handler om “Big Data” for tiden, og det er indlysende, at den voksende trang til at analysere store datamængder også bør præge medierne i 2015. Muligvis vil de – som det ser ud til at gælde JP/Politiken – være mest optaget af at analysere egne kundedata, så de bedst muligt kan holde på læserne/brugerne og måske tiltrække nye.
Medierne – ikke mindst Politiken – har skrevet meget om Big Data i 2014. Vi har endnu ikke set megen journalistik baseret på analyser af store datamængder. Men mon vi ikke også i 2015 vil se eksempler på det? Der er masser at gå i gang med.
Selv om de data, som myndighederne foreløbig af egen drift har stillet til rådighed for andre gennem “open data” initiativer er noget tamme, så er der bestemt muligheder her. Prøv bare at tage et kig på de data, som stilles til rådighed af henholdsvis Odense, Aarhus og Københavns kommuner.
No comments yet.